RAG (Retrieval-Augmented Generation)
- A beginner-friendly walkthrough of RAG fundamentals with LangChain context.
- Explains why retrieval quality drives answer quality and what to prioritize first in chain design.

What is RAG
You can often encounter the term 'RAG' in LLM-related articles or LangChain, OpenAI Assistants documentation. RAG (Retrieval-Augmented Generation) is translated as 'retrieval-augmented generation' in Korean, but it feels difficult to understand what this means.
To understand it more easily, we can use question-answer (Q&A) chatbots, which are representative LLM services that use RAG, as an example.
While LLMs can reason about a wide range of topics on their own, these results are limited to public data up to a specific point in time used for model generation. For example, a model trained on data up to 2018 doesn't know about events, information, or private data that occurred after that.
It doesn't just stop at not knowing but sometimes creates incorrect answers, and these errors are called 'hallucinations'.
To solve these problems, the method of inserting necessary information into prompts is called RAG.
RAG Architecture
RAG architecture mainly consists of two major components:
Indexing: A pipeline for collecting and indexing data from sources. This process usually happens offline.
Retrieval and Generation: The actual RAG chain that takes user queries at runtime, retrieves relevant data from the index, and passes it to the model.
The most important reason for distinguishing between indexing and retrieval/generation is the size of data.
For example, let's assume there's a 100-page document about company services. If we pass the user's question and the entire 100-page content as a prompt to an LLM, the prompt itself becomes very large, increasing the probability of receiving inaccurate answers from the LLM.
Also, if you use services like OpenAI instead of your own LLM, costs increase.
Number of tokens = Cost
Now let's look at indexing and retrieval and generation in more detail.
Indexing
In this step, documents are separated into chunks, i.e., small units. After that, instead of storing text as is, text embedding models are used to convert text into vector values. The vectorized values are stored in vector databases, which are used for similarity search in later steps.
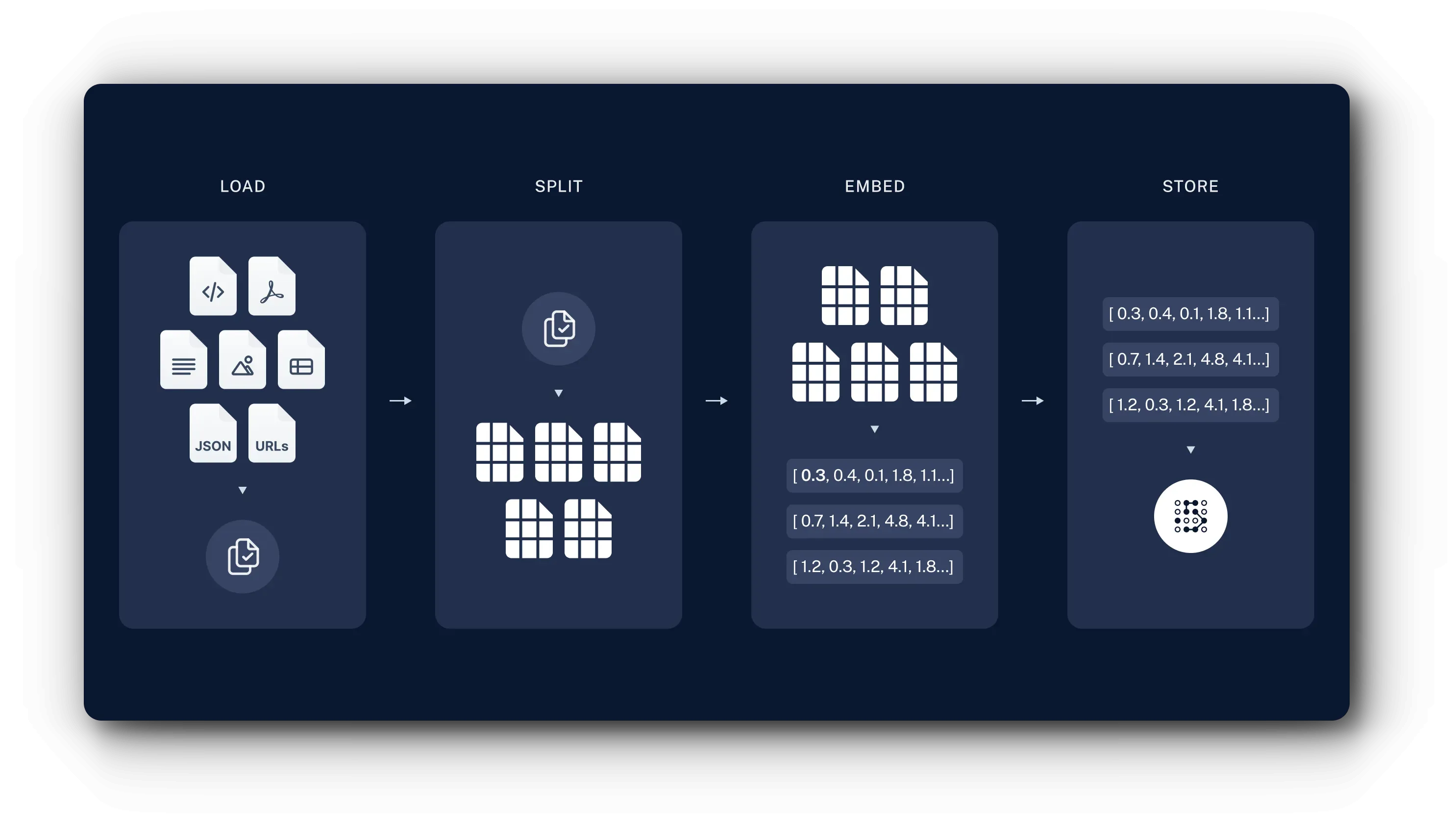
The indexing process using LangChain is as follows:
- Load: First, you need to load data. This uses DocumentLoaders.
- Split: Text splitters divide large documents into smaller chunks. This is useful for indexing data and passing it to models, because large chunks are difficult to search and don't fit in the model's finite context window.
- Store: You need a place to store and index the split data so it can be retrieved later. This is done using VectorStore and Embeddings models.
Through this process, documents are separated into chunks and stored. The data stored this way is used in the next retrieval and generation step.
Retrieval and Generation
- Retrieval: Given user input, use Retriever to perform similarity search on stored chunks.
- Generation: ChatModel / LLM generates answers using prompts that include the question and retrieved data.
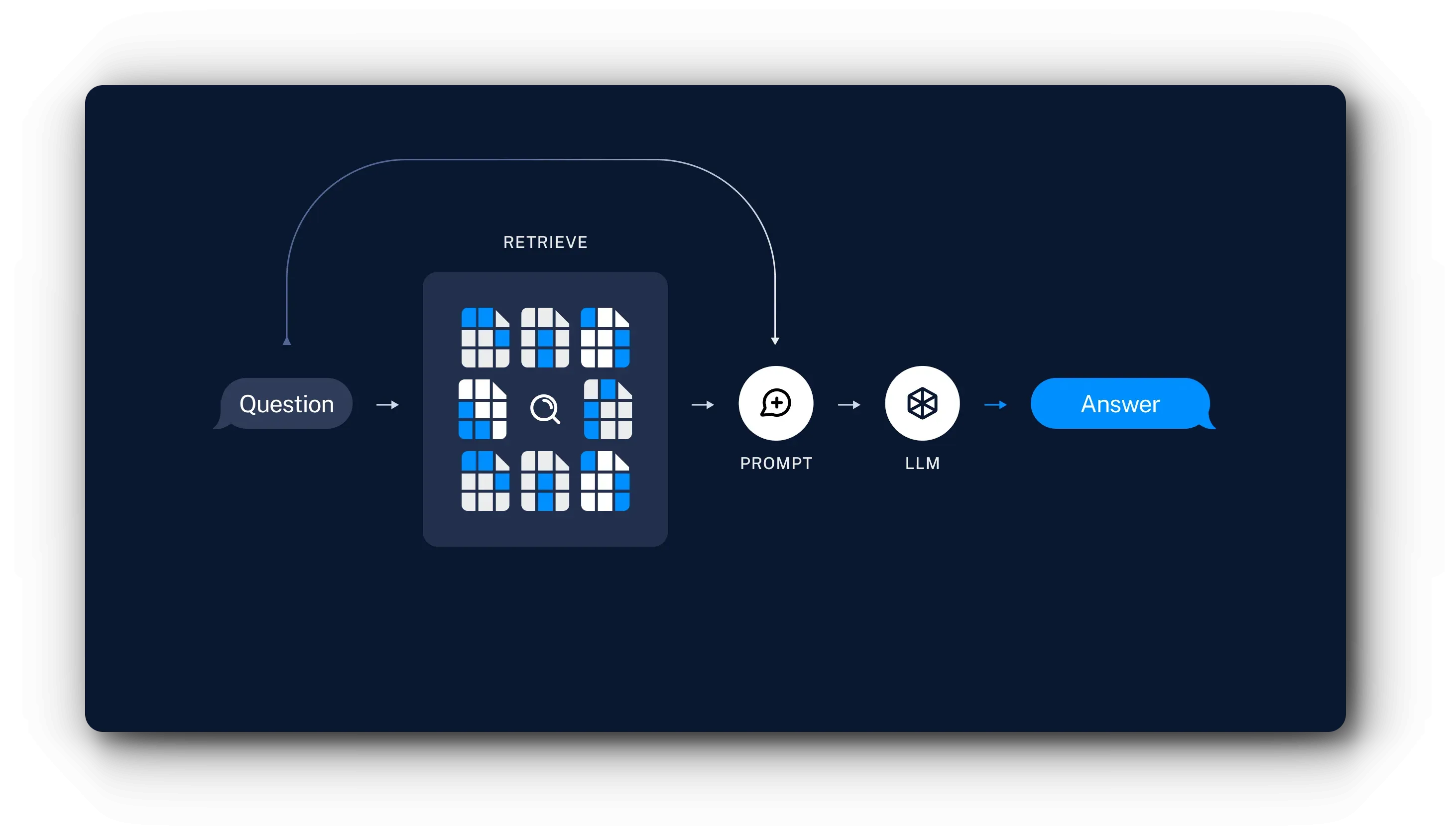
As shown above, the goal of RAG architecture is to prevent LLM hallucinations and generate more accurate responses with fewer tokens.
Chains
LangChain provides Retriever and Document Chain to easily use these steps. This section explains how Document Chain implemented in LangChain works, not actual chain usage.
LangChain recently launched version 0.1.0 and classified previously used Chains as Legacy Chains. Document Chain is also included in this.
https://python.langchain.com/docs/modules/chains/#legacy-chains
According to the page above, legacy chains removed in 0.1.0 are scheduled to be rewritten and return in version 0.2.0.Stuff
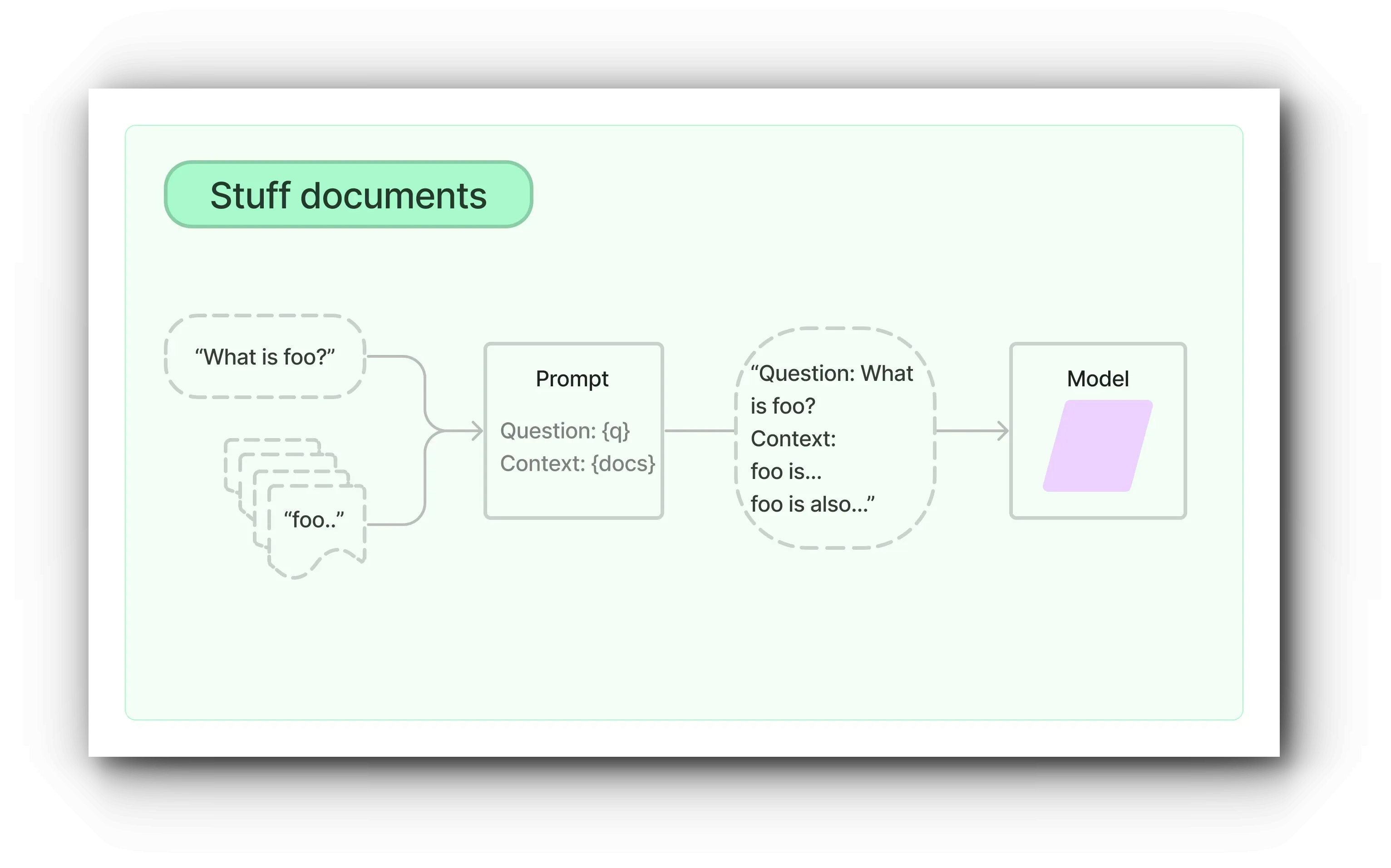
The Stuff Documents chain is the most basic chain among the processes described earlier. This chain performs similarity search on the list of indexed documents to get results, and based on this, retrieves document chunks to generate prompts.
Refine
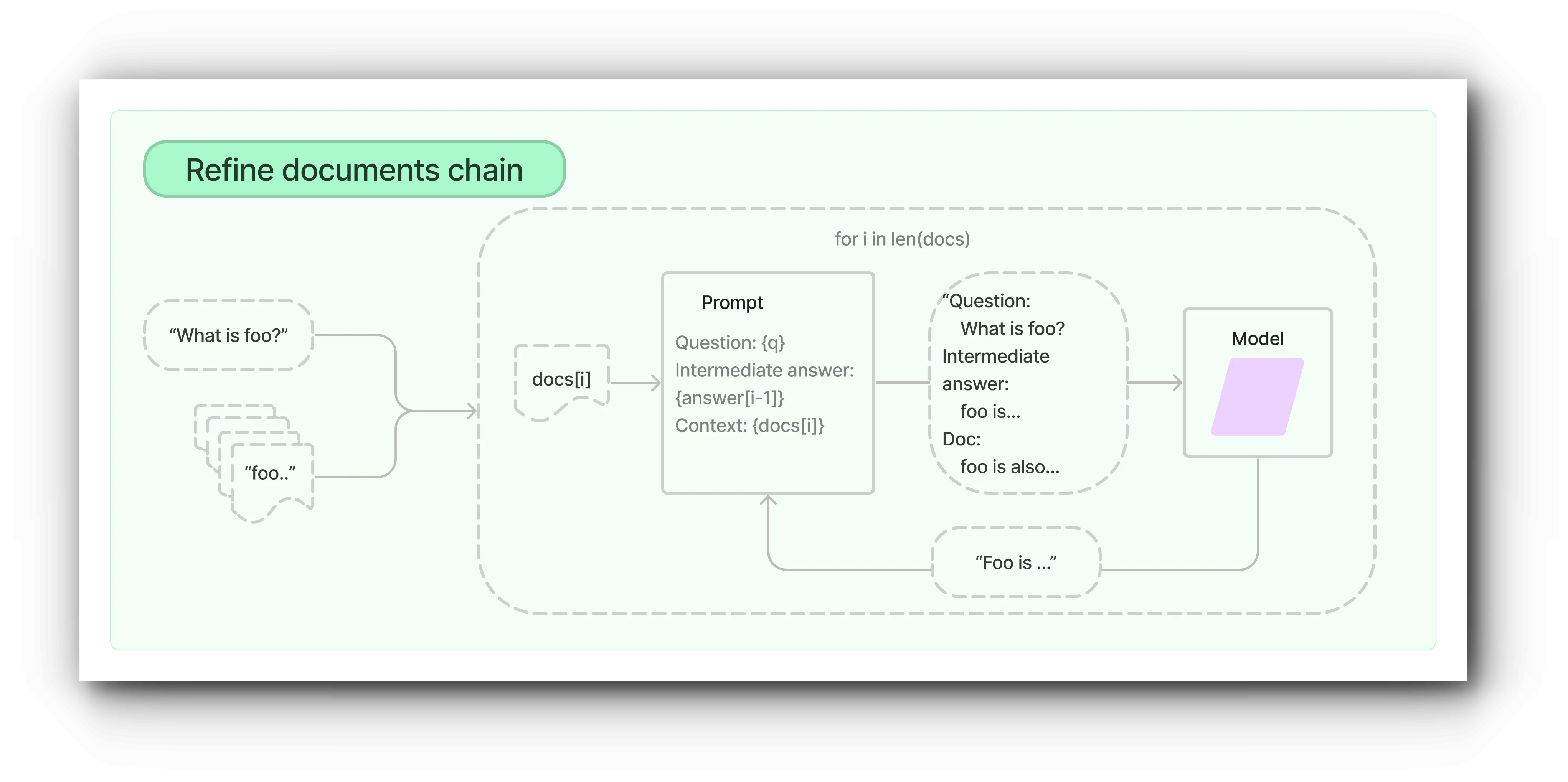
The Refine document chain iteratively processes input documents and constructs responses by continuously updating answers during this process. This chain passes all non-document inputs, the current document, and the most recent intermediate answer to the LLM chain for each document to get new answers.
For example, if there are 10 related documents, the chain receives a response for the first document and generates the next prompt based on that response. This process is repeated for 10 documents to return the final result.
The advantage of this method is that it can analyze more documents. However, the disadvantages are that it requires more LLM calls and takes more time to generate results because it's not parallel processing.
MapReduce
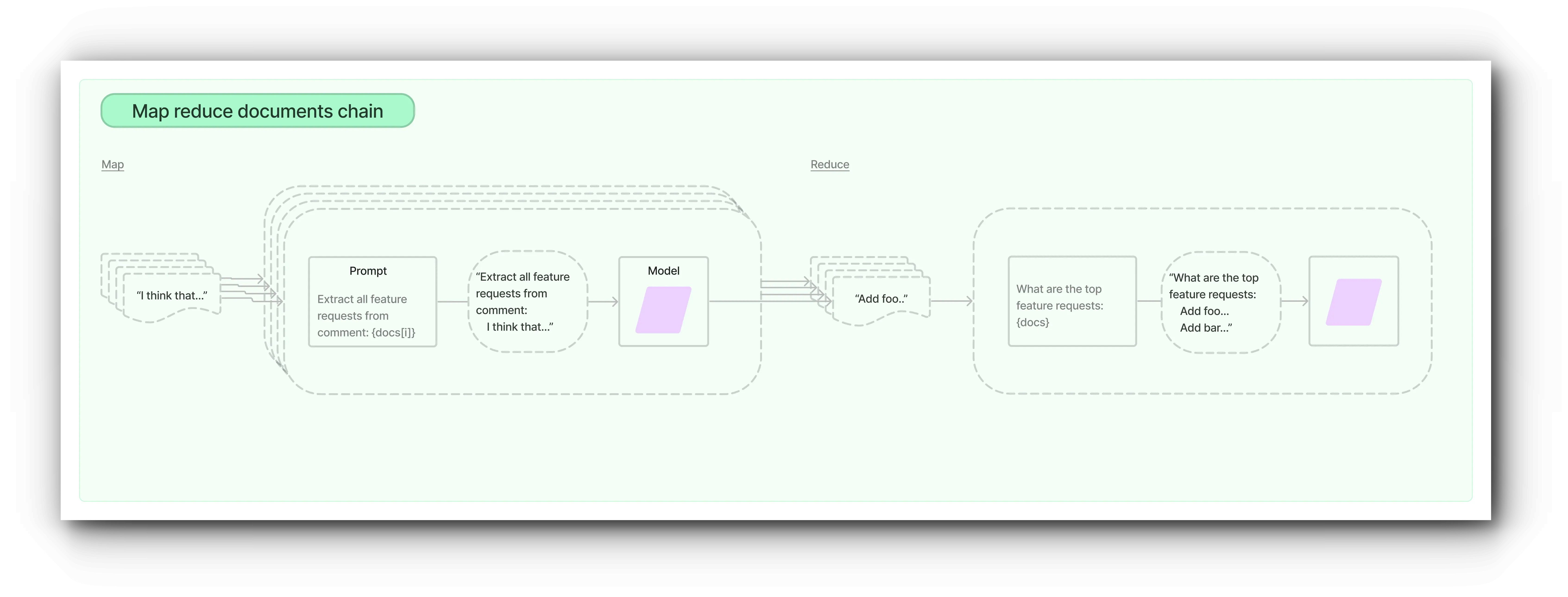
The map reduce document chain first applies an LLM chain individually to each document (map step) and treats the chain output as new documents.
Then it passes all new documents to a separate document combining chain to get a single output (reduce step). Optionally, mapped documents can be first compressed or reduced to ensure they fit the document combining chain (often passed to LLM). This compression step is performed recursively if necessary.
MapRerank

It generates separate prompts for documents and passes them to the LLM simultaneously in parallel. During this process, it returns results including scores for the results. This allows selecting results with high scores, i.e., high reliability, among all responses.
This method is useful when there are many documents and is suitable when you want to generate answers based on a single document without combining answers like Refine and Reduce methods.
Conclusion
During writing, many changes occurred in the Chain part due to LangChain's 0.1.0 update. Not only LangChain but AI technology in general is developing rapidly, which can be difficult for learners, but this development is also an interesting part.
References
- https://netraneupane.medium.com/retrieval-augmented-generation-rag-26c924ad8181
- https://python.langchain.com/docs/use_cases/question_answering/
- https://js.langchain.com/docs/modules/chains/document
- https://js.langchain.com/docs/modules/chains/document/stuff
![[Book Review] Learning LangChain: Implementing RAG, Agents, and Cognitive Architecture with LangChain and LangGraph](/_astro/review-learning-langchain-20250629212214926.MxZbPAfN.webp)

