[Book Review] The Math Behind AI
- Instead of building math concepts first, the book starts from real AI use cases and naturally connects to the math you need.
- It has an approachable entry barrier for developers who want to study AI but feel rusty with math.
- The explanations are very detailed (476 pages), so I recommend reading it with enough time.

"This review was written after receiving a complimentary copy of the book as part of Hanbit Media's <I am a Reviewer> program."The Math Behind AI
TL;DR: Instead of explaining math concepts first, this book starts from real AI cases (recommender systems, image classification) and naturally leads you to the math required to build them. For developers who want to study AI but have become distant from math, this is an approachable AI math book.
Book Info
- Title: The Math Behind AI
- Publisher: Hanbit Media
- Author: Toru Furushima
Toru Furushima is the CEO of cross-X. After graduating from the Faculty of Law at Kyoto University, he worked at consulting and IT companies before founding cross-X. At a consulting company, he led data and AI strategy projects. At an IT company, he built experience in business operations, including management, business control, IPO, and fundraising. He now supports digital transformation consulting for large enterprises and helps train DX talent.
Growing Distant from Math
When you work in web development, you gradually drift away from math. You may still need it when implementing certain algorithms, but in day-to-day work, math rarely appears directly.
On top of that, so many algorithms are already implemented as libraries, so there is even less reason to dig deep.
Still, I have continued to stay interested in game development, so I occasionally read math books related to game dev. As the AI era accelerated, though, even the direction of math books changed. More and more books are now focused on AI.
That is how I picked up this book, and while reading it, I realized its approach is quite different from other math books.
How It Differs from Typical Math Books
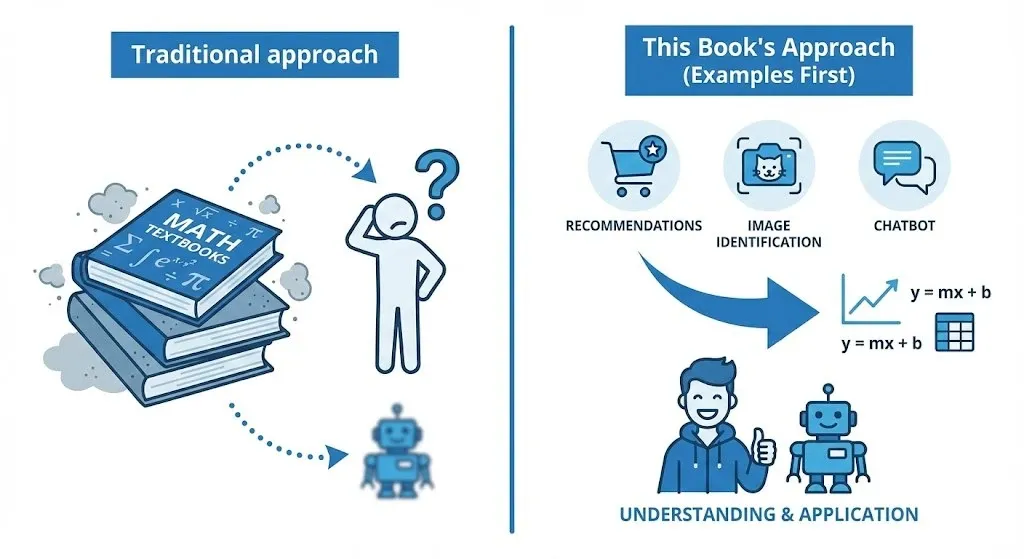
Most math books follow a sequence similar to school textbooks: easy concepts first, difficult concepts later. They build concepts first and place applications on top.
This book does the opposite. It shows real use cases first, then naturally connects them to the math needed to implement those functions.
The book makes this intended difference very clear early on with a diagram. The main point is this:
- Typical structure: even when formulas are introduced first (or topics are explained), it is easy to skip "why this formula is needed here" and "how the intermediate calculations connect"
- This book's structure: it explains each chapter around a concrete topic, but introduces formulas at the exact moment they are needed and does not skip intermediate calculation steps
Because of this, beginners are less likely to have the "a formula suddenly appears and I get lost" experience, and there is more room to follow along and understand.
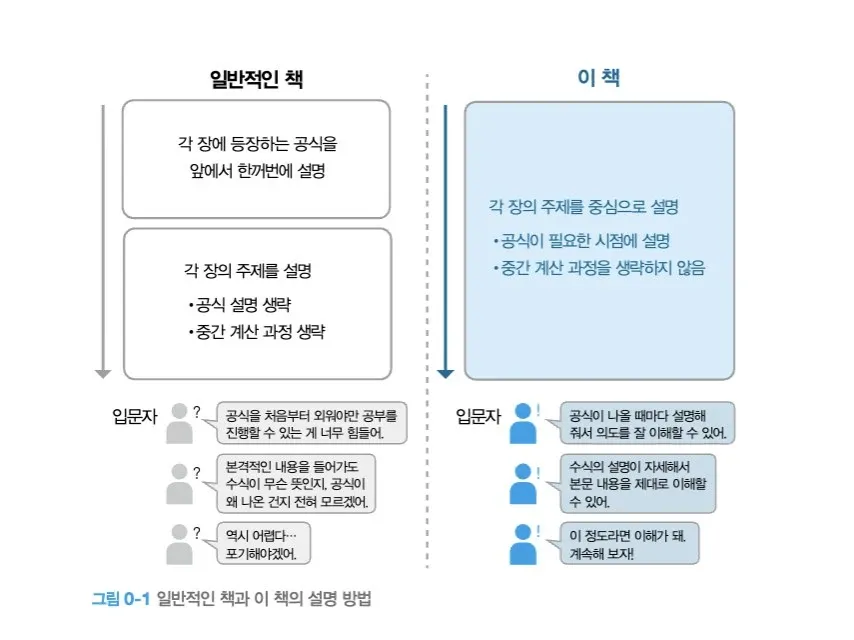
(Image) A concept map I made to help explain this post
And the first example is recommender systems.
A Journey That Starts with Recommender Systems
The book introduces methods for predicting ratings from both user and product perspectives, and even covers recommendations from a serendipity point of view. In that process, loss functions and gradient descent appear naturally.
If you have studied machine learning, these concepts are familiar. But in this book, those concepts come in after you already understand why they are needed in the context of implementing recommender systems, so they feel much more natural.
This is where I felt, "The approach here is different."
CNN: Deeper Than Expected
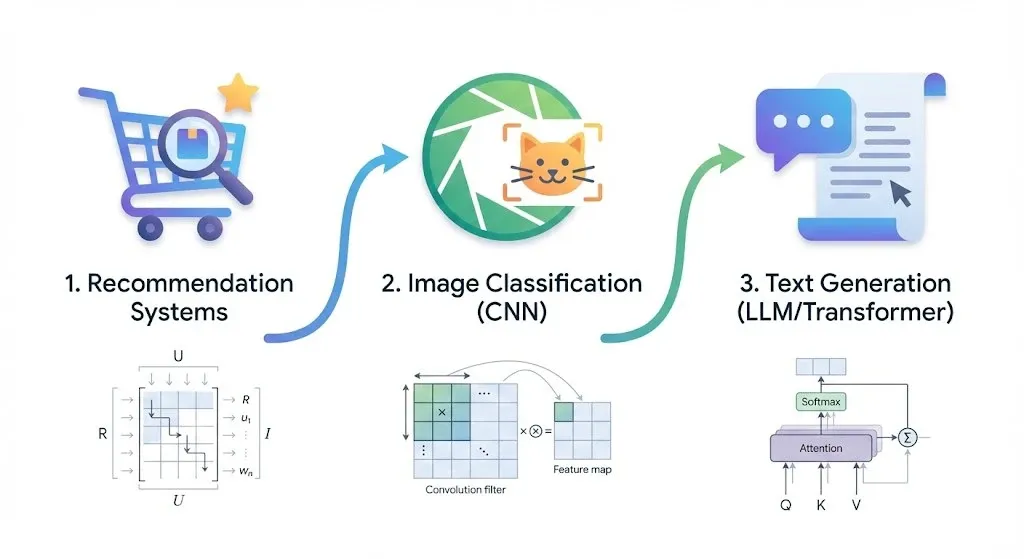
After the recommender-system chapter, the book moves to image classification. It explains how convolutional neural networks (CNNs) process images, and among the AI books I have read, not many cover this topic at this depth.
It also mentions the model that won the 2012 ImageNet competition with overwhelming performance. The name is not explicitly stated in the book, but this event is so well known in deep-learning history that I immediately thought, "This is about AlexNet."
The book also covers how CNNs evolved afterward, and this section is clearly deeper than many other books.
LLMs: The Math of Text Generation
After CNNs, the book moves on to LLMs. How is text generated? The starting point is the Transformer architecture. It began with Google's paper, "Attention Is All You Need," and is now widely used beyond text, including multimodal, speech, and vision models.
When trying to understand Transformers before, I once studied each part at https://bbycroft.net/llm, and this book takes a similar approach.
When you first open the pages, the formulas can feel overwhelming, but if you go through them one by one, they are understandable. The book does not stop at "it works like this"; it also explains "why this calculation is needed" at each stage. By the end, instead of using LLMs as a pure black box, you gain at least a rough picture of what is happening inside.
The tradeoff is reading time. Out of six total chapters, I have only finished four so far. The later part is said to cover math used in speech and positioning, and I plan to add more after finishing the book.
476 Pages of Thorough Explanation
There are only six chapters. But the total length is 476 pages, and most of those pages are spent on formula development and explaining the flow.
Depending on the chapter topic, formulas are developed step by step, and the conceptual flow is explained in plain terms. The common thread is that the book does not hesitate to spend pages so readers can eventually understand.
It is not easy. But if you read steadily, you do understand in the end. Rather than just listing equations, the book explains in order why each one appears, which made it easier not to give up and keep following.
Closing Thoughts
For web developers who have become distant from math but want to understand how AI works, this is a book with a relatively low barrier to entry. Because it follows a "cases first, math later" flow, I could read without constantly asking, "Why do I need to learn this?"
That said, it is a long-read book, so I recommend setting aside enough time.
Refs
- 한빛미디어 「AI를 움직이는 수학 이야기」: https://www.hanbit.co.kr/store/books/look.php?p_code=B2593246869
- AlexNet (Wikipedia): https://en.wikipedia.org/wiki/AlexNet
- Krizhevsky et al. (2012), ImageNet Classification with Deep Convolutional Neural Networks, NeurIPS
- Vaswani et al. (2017), Attention is All You Need, NeurIPS
- LLM Visualizer: https://bbycroft.net/llm
![[Book Review] Essential Math for Developers](/_astro/review-essential-math-for-data-science-20240627155310251.BhKlJd0p.webp)
![[Book Review] Visualizing Generative AI](/_astro/review-visualizing-generative-ai-cover.BA0TjpHs.webp)
![[Book Review] Fundamentals of Deep Learning 2nd Edition](/_astro/review-fundamentals-of-deep-learning-2nd-edition-20240217134412538.Dmvk9gCE.webp)