
들어가기 전
만약 AI에 관심이 있고 Stable Diffusion이나 OpenAI와 같은 LLM을 어떻게 사용할지, 또는 무엇이 가능한지 알아보고 싶다면, 딥러닝을 배우기보다는 프롬프트 엔지니어링에 대해 공부하는 것을 추천합니다.
하지만 근본적으로 어떻게 동작하는지 이해하고자 한다면, 이 책이 좋은 선택일 수 있습니다. 단, 이 책은 다소 난이도가 있습니다.
딥러닝에 대한 기초 지식을 쌓은 후에 읽으면 더 좋습니다. 추천 서적은 맨 아래 후기 추가하였습니다.
소개
『딥러닝의 정석 (2판)』은 딥러닝의 기본과 본질에 집중하여 독자들이 폭넓은 이론과 실무 지식을 습득할 수 있도록 구성되어 있습니다. 초반에는 딥러닝 이해에 필요한 수학적 배경지식인 선형대수학과 확률을 살펴보고, 신경망의 기본 원리와 함께 순방향 신경망의 구조, 순방향 신경망을 PyTorch 실습 코드로 구현하는 방법, 실제 데이터셋에서 순방향 신경망을 훈련하고 평가하는 방법 등을 상세하게 다룹니다. 또한 경사하강법, 최적화, 합성곱 신경망, 이미지 처리, 변이형 오토인코더 등 실전에서의 딥러닝 구현 능력을 향상할 수 있도록 도와주고, 딥러닝의 특정 응용 분야와 신경망 아키텍처를 깊이 이해하는 데 집중합니다.
후반부에는 시퀀스 분석 모델, 생성 모델, 그리고 해석 가능성 방법론 등에 대한 이론과 실무 지식을 제공해 최신 동향을 반영하여 각 분야에 딥러닝을 어떻게 적용하는지 설명합니다. 이 책은 딥러닝의 기본부터 심화 내용까지 아우르며, ‘정석’이라는 이름에 걸맞게 한 권으로 딥러닝 기술을 마스터할 수 있는 완벽한 가이드입니다.2판에서 달라진 점
선형대수, 확률, 생성 모델, 해석 가능성 방법론이 추가되었습니다. 1판에서는 TensorFlow를 사용했으나, 2판에서는 PyTorch를 사용합니다.
요약
1~2장에서는 선형대수와 확률의 기초를 다룹니다. 이 장들은 머신러닝을 공부하기 전에 알아야 할 선형대수와 확률에 대해 간략히 설명합니다.
선형대수에서는 행렬 연산, 벡터 연산, 행렬-벡터 곱셈, 공간 및 고유벡터와 고윳값에 대해 설명합니다. 확률 기초에서는 확률 분포, 조건부 확률, 확률 변수, 기대값과 분산을 다룹니다.
3~5장은 신경망을 다룹니다. 머신러닝의 기본 개념을 소개하고, 전통적인 컴퓨터 프로그램의 한계를 극복하기 위해 딥러닝을 사용하는 이유와 인간 두뇌의 뉴런과 유사한 개념인 인공 신경망에 대해 설명합니다.
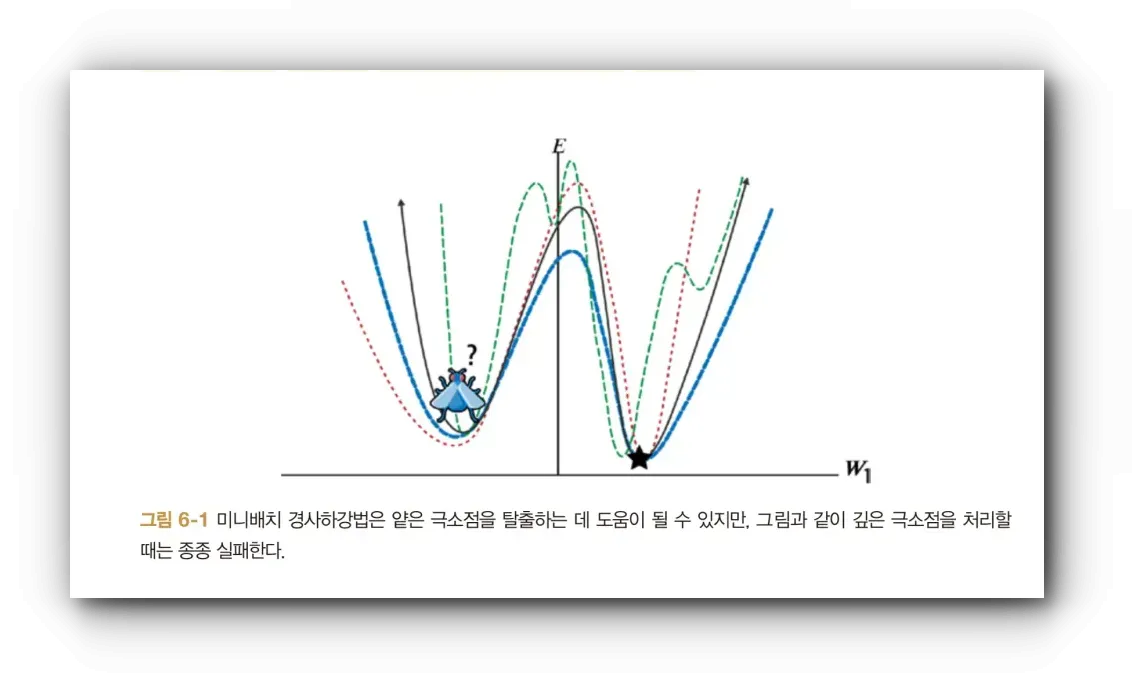 그리고 5장부터는 경사하강법, 역전파 알고리즘, 테스트/검증/과적합을 소개하며 PyTorch를 사용하여 인공 신경망을 구현해 봅니다.
그리고 5장부터는 경사하강법, 역전파 알고리즘, 테스트/검증/과적합을 소개하며 PyTorch를 사용하여 인공 신경망을 구현해 봅니다.
(MNIST 트레이닝 데이터셋 사용)  6장에서는 경사하강법을 더 깊게 다룹니다.
6장에서는 경사하강법을 더 깊게 다룹니다. 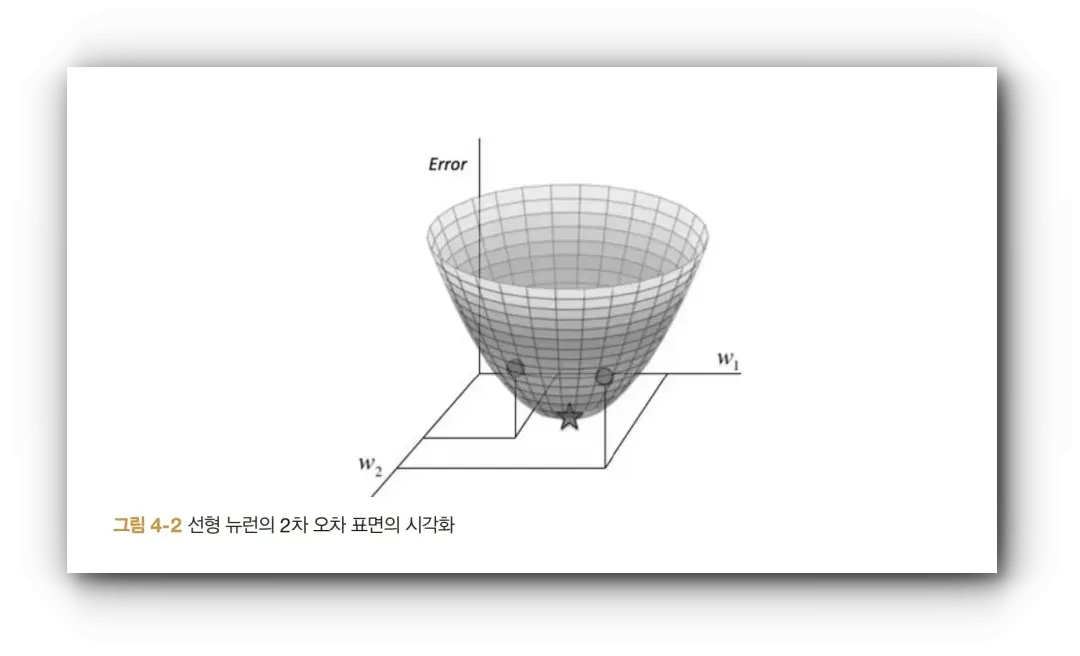 이 장에서는 Global minimum에 효율적으로 도달하기 위한 여러 최적화 기법을 설명합니다. 예를 들어, 미니배치 경사하강법, 모멘텀을 사용한 미니배치 경사, RMSProp, 모멘텀을 사용한 RMSProp, Adam 등이 있습니다.
이 장에서는 Global minimum에 효율적으로 도달하기 위한 여러 최적화 기법을 설명합니다. 예를 들어, 미니배치 경사하강법, 모멘텀을 사용한 미니배치 경사, RMSProp, 모멘텀을 사용한 RMSProp, Adam 등이 있습니다.
7장 합성곱 신경망
전통적인 이미지 분석 방식의 한계와 현재 사용되는 합성곱 신경망에 대해 설명합니다. 합성곱 신경망은 시각적 이미지 분석, 음성 인식, 사물 이미지 인식에 주로 사용됩니다.
ImageNet 경진대회에서 2011년 우승자의 25.7% 오류율을 다음 해 몇 달 만의 연구로 16% 오류율을 달성한 합성곱 신경망 아키텍처로 혁신을 이뤄냈습니다.
기본 심층 신경망이 이미지가 커질수록 확장성이 떨어지고 과적합 문제를 야기하는 반면, 합성곱 신경망은 인간의 시각 작동 방식에서 영감을 받아 뉴런이 3차원으로 배열되어 각 레이어마다 볼륨을 가집니다.
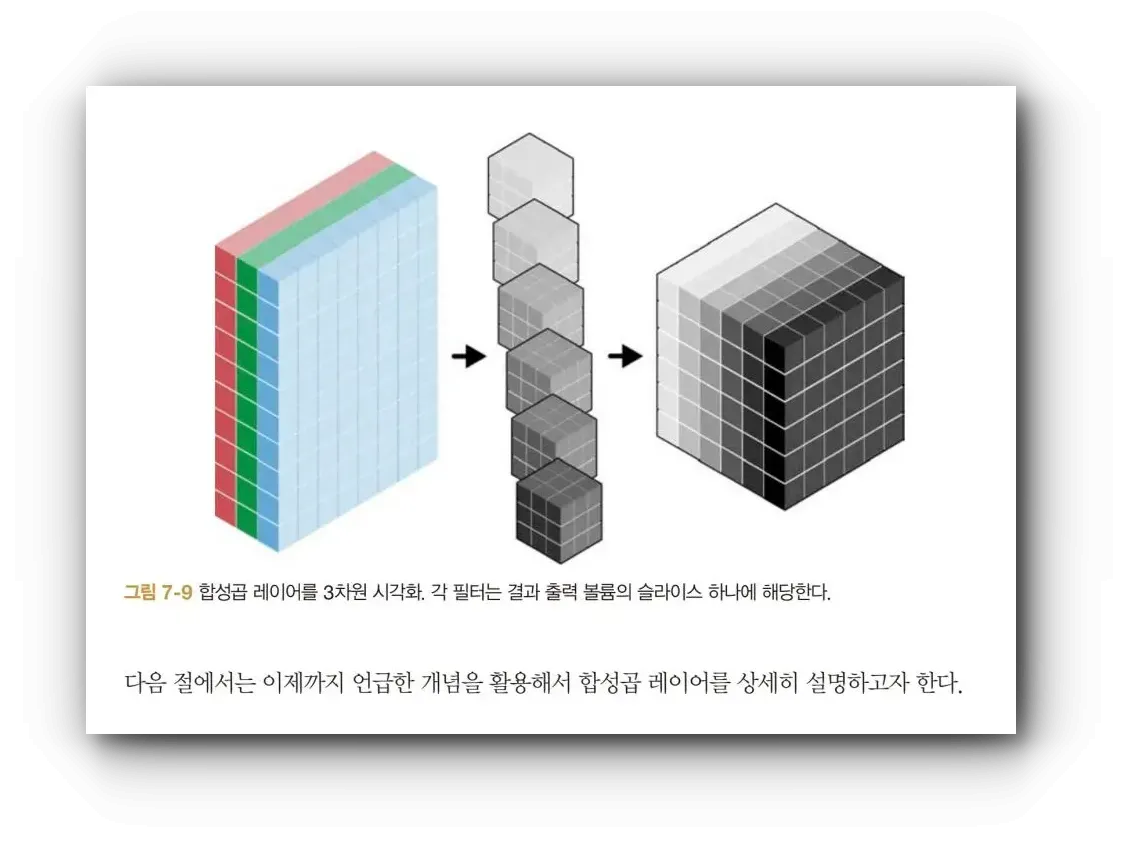 특히 마지막 섹션이 흥미로운데, 합성곱 필터를 활용한 예술 스타일 재현을 위해 neural style 알고리즘을 사용해 유명 아티스트의 화풍으로 사진을 렌더링 하는 결과를 보여줍니다.
특히 마지막 섹션이 흥미로운데, 합성곱 필터를 활용한 예술 스타일 재현을 위해 neural style 알고리즘을 사용해 유명 아티스트의 화풍으로 사진을 렌더링 하는 결과를 보여줍니다.
왼쪽 사진의 스타일적 특성을 추출 한 후, 일반 진에 적용하여 아래와 같은 새로운 이미지를 생성합니다.  8장 임베딩과 표현 학습
8장 임베딩과 표현 학습
임베딩 생성 방법을 설명합니다. LLM이나 LangChain을 사용하며 데이터를 벡터로 임베딩해서 쓸일은 많았지만, 실제로 생성 과정에 대해서는 잘 모르기 때문에 흥미로웠습니다.
10장 생성 모델
이전 장까지는 판별 모델에 대해 이야기했으며, 이 장에서는 생성 모델을 다룹니다.
GAN(Generative Adversarial Network, 생성적 적대 신경망)은 Generator와 Discriminator 두 신경망이 서로 경쟁하며 학습하는 모델입니다. Generator는 진짜와 구분할 수 없는 가짜 데이터를 만들어내려고 하고, Discriminator는 받은 데이터가 진짜인지 가짜인지를 판별합니다. 이 과정을 통해 Generator는 점점 더 현실적인 데이터를 생성하게 됩니다.
VAE(Variational Autoencoder, 변이형 오토인코더)는 입력 데이터를 잘 표현하는 잠재 공간을 학습하는 모델입니다. VAE는 데이터의 효율적인 압축과 생성을 목적으로 하며, 입력 데이터를 잠재 변수에 매핑한 후 이를 다시 원본 데이터로 복원하는 구조를 가집니다. VAE는 데이터의 확률적 특성을 모델링하여 새로운 데이터를 생성할 수 있습니다.
13장 강화학습
알파고의 성공 이후 많은 주목을 받은 강화 학습에 대해 다룹니다. 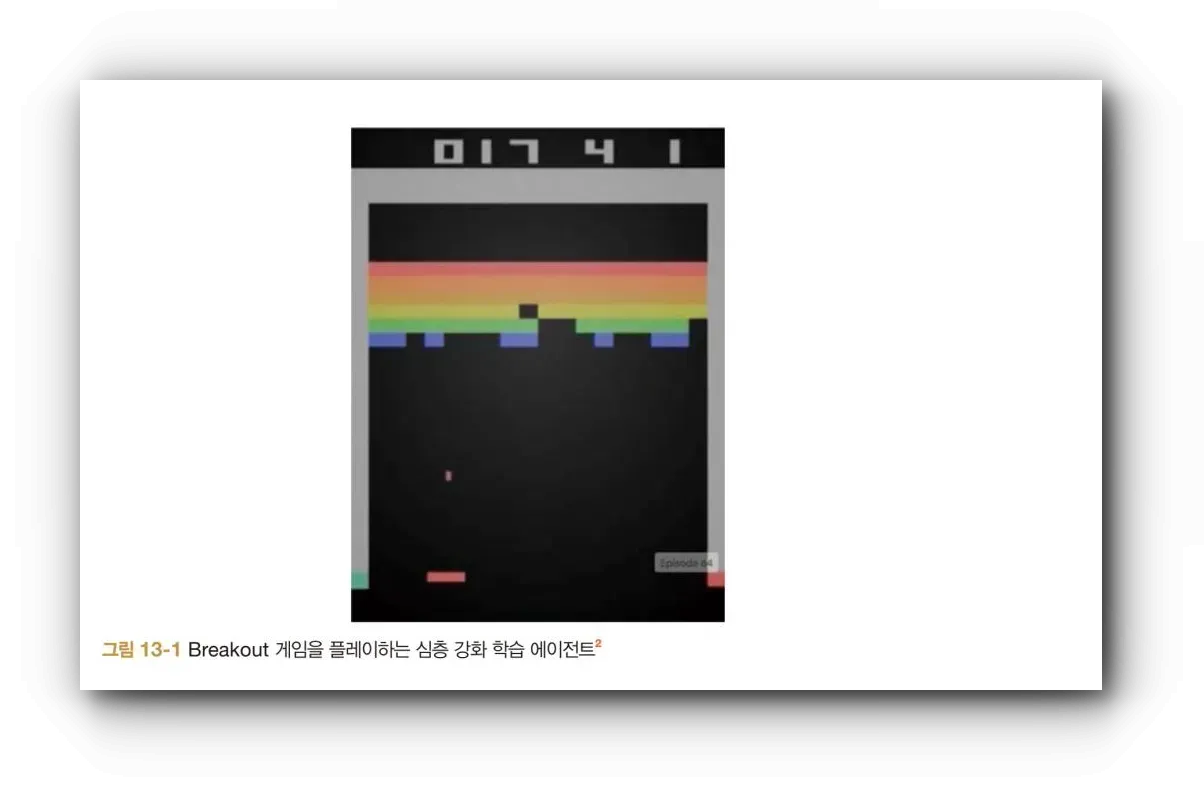 OpenAI Gym을 사용한 강화 에이전트 개발 예제와 함께, 딥마인드가 DQN을 사용한 이유와 새로운 게임마다 재훈련이 필요한 문제에 대한 개선책인 DRQN, A3C, UNREAL 등의 기법이 소개됩니다.
OpenAI Gym을 사용한 강화 에이전트 개발 예제와 함께, 딥마인드가 DQN을 사용한 이유와 새로운 게임마다 재훈련이 필요한 문제에 대한 개선책인 DRQN, A3C, UNREAL 등의 기법이 소개됩니다.
후기
8장까지 읽는데 페이지의 압박으로 머리 아파서 9장 (시퀀스 분석), 11장 (해석가능한 방법론), 12장 (메모리 증강 신경망)은 스킵하고 흥미로운 장 먼저 봤네요. 나중에 마저 볼 예정 :)
AI 관련 기능 프로젝트를 하며, 최근 PyTorch을 막 쓰기 시작해서 익숙하지 않았는데 5장이 많은 도움이 되었습니다, 특히 PyTorch 텐서 속성과 연산 설명이 너무 잘 정리되어서 좋았습니다.
책이 컬러여서 좋습니다.
관련 도서 및 코스 한빛 미디어에서는 함께 읽으면 좋은 도서로 아래 도서를 권장하고 있습니다.
- 밑바닥부터 시작하는 딥러닝4
- 핸즈온 머신러닝(3판)
- 케라스로 구현하는 딥러닝
개인적으로 온라인 코스인 코세라 Andrew Ng 교수의 Machine Learning Specialization를 추천하며 Andrew Ng 교수가 만든 Deeplearning.ai 에도 많은 AI, AGI 관련 코스들이 공개되어 있습니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."