[도서 리뷰] LLM 서비스 설계와 최적화 - 비용은 낮추고 성능은 극대화하는 AI 서비스 구축과 운영 가이드
- LLM 서비스 설계/최적화 도서를 비용·성능·운영 균형 관점으로 리뷰했습니다.
- 모델 선택보다 중요한 시스템 설계 포인트를 짚어, 실서비스 수준 판단에 도움을 줍니다.

"한빛미디어 서평단 <나는리뷰어다> 활동을 위해서 책을 협찬 받아 작성된 서평입니다."LLM 서비스 설계와 최적화
이번에 리뷰하게 된 책은 'LLM 서비스 설계와 최적화'입니다.
LLM 등장 이후 수많은 서비스에서 AI 기능들이 우후죽순 생기고 있습니다. 저도 회사 서비스에 지난 2년간 디퓨전 모델을 사용한 이미지 생성이나 LLM을 사용한 콘텐츠 생성 AI 관련 업무를 하고 있는데, 이 책을 보니 그간 느꼈던 점들에 많이 공감되고 배울 것이 많았습니다. AI 서비스 개발이 이제는 과도기에 접어들었다고 생각합니다. 아직 AI 서비스의 시스템 설계나 로직들의 표준이 정의되지 않아 혼란을 겪고 있는 사람들이 많겠지만, 이 책을 통해 어느 정도 가이드라인을 잡아볼 수 있을 것 같습니다.
저자 소개
Dr. Shreyas Subramanian은 Amazon Web Services의 수석 데이터 과학자로, AI와 기계 학습 분야에서 다양한 기여를 통해 중요한 발전을 이루었습니다. 특히 AWS 기계 학습 인증과 기계 학습을 활용한 고성능 컴퓨팅에 관한 그의 저서들은 아마존 AI 분야 베스트셀러 10위 안에 들며 그의 전문성을 입증합니다. Dr. Subramanian은 또한 여러 영향력 있는 연구 논문을 저술하여 AI 학술 담론을 더욱 풍부하게 했습니다. 최근 몇 년간 개발한 여러 특허들은 그의 혁신적인 업적을 더욱 잘 보여줍니다. 또한 Dr. Subramanian은 AWS 기계 학습 블로그를 통해 Amazon SageMaker에 기계 학습 모델 배포, 대규모 모델 훈련, 서버리스 추론 함수 구축과 같은 주제에 대한 지식과 통찰력을 공유하며, 복잡한 개념을 더 넓은 대중을 위해 단순화하는 능력을 보여주고 있습니다.
책 소개
대형 언어 모델을 활용한 비용 효율적인 앱 구축 방법 학습
"Large Language Model-Based Solutions: How to Deliver Value with Cost-Effective Generative AI Applications"(대형 언어 모델 기반 솔루션: 비용 효율적인 생성형 AI 애플리케이션으로 가치 제공하는 방법)에서 Amazon Web Services의 수석 데이터 과학자인 Shreyas Subramanian은 비용 효율적인 대형 언어 모델(LLM) 기반 솔루션을 구축하고 배포하고자 하는 개발자와 데이터 과학자들을 위한 실용적인 가이드를 제공합니다. 이 책에서는 모델 선택 방법, 데이터의 전처리 및 후처리, 프롬프트 엔지니어링, 명령어 미세 조정 등 주요 주제를 폭넓게 다룹니다.
기본 모델을 배포하는 데 관심이 있는 개발자와 데이터 과학자 또는 GenAI 사용을 확장하려는 비즈니스 리더에게 완벽한 이 책은 프로젝트 리더와 관리자, 기술 지원 직원, 그리고 이 주제에 관심이나 이해관계가 있는 관리자들에게도 도움이 될 것입니다.
책 리뷰
목차
1장 LLM 기초
LLM의 역사와 개념을 설명합니다. 이 책이 다른 책과 다른 점은 1장부터 비용 계산 스냅샷이나 벤치마크 결과 그리고 개념을 좀 더 자세히 다루고 있습니다. 그리고 LLM에 대한 개념을 넘어서 AI 서비스 구축에 필요한 인프라 계층, 모델 계층, 애플리케이션 계층을 분리하여 설명하고 있습니다. 실제 서비스 배포 시 고려해야 할 비용 최적화에 대해서도 이야기합니다.
2장 비용 최적화를 위한 튜닝 기법 그리고 바로 2장부터 튜닝 기법으로 들어갑니다. P-튜닝, LoRa와 같은 최신 방법을 다루며, 전체 훈련에 들어가는 천문학적인 비용이 이를 통해 어떻게 절감되는지에 대해 설명과 함께 표로 보여줍니다.
3장 비용 최적화를 위한 추론 테크닉
프롬프트 엔지니어링, 캐싱, 배칭 같은 인퍼런스 모델 최적화 방법을 제시합니다. 제로샷, 퓨샷, COT 등과 벡터 스토어를 이용한 캐시 같은 전통적(?) 방식은 물론, 배칭 프롬프트, 랭체인을 이용한 체이닝 등 여러 방법을 소개하며, 이를 어떻게 결합하여 전체적인 서비스를 구축할지에 대한 내용을 다룹니다.
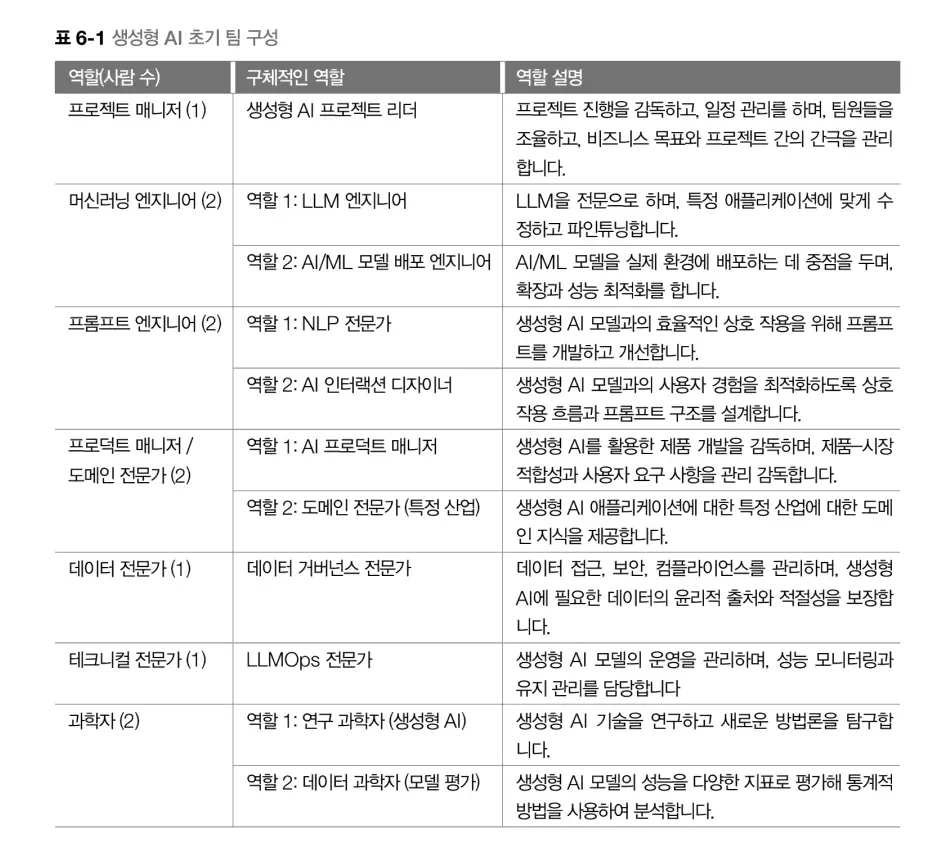
4장 모델 선택과 대안
모델 선택에 있어서 어느 정도 가이드를 제공합니다. 소형모델(SML), 대형모델(LLM)에 대해 다루고, 특정 분야에 대한 도메인 특화 모델에 대해 이야기합니다. 자체 토크나이저를 학습해서 특정 도메인 전문화를 어떻게 하는지 다루고, 또한 반대로 파인튜닝 없이 일반 모델로 프롬프트 엔지니어링을 통해 도메인 특정 모델과 비슷한 성능을 낼 수 있는지에 대해서도 설명합니다.
예를 들면 claude-3.7-sonnet, gpt-4, gpt-3.5, gpt-o3와 같은 구체적 모델이 아닌, 더 큰 범주에 대해 다루고 있으니 참고하시기 바랍니다.
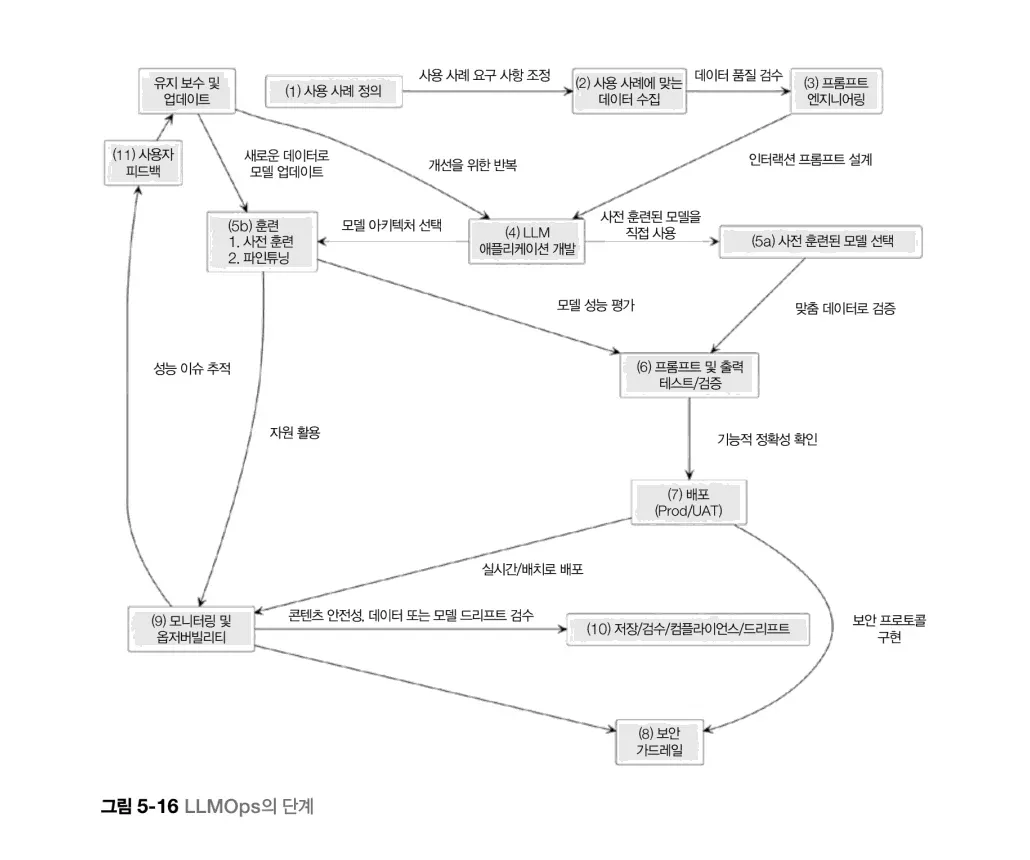
5장 인프라 및 배포 튜닝 전략
메모리, 캐싱, 비용, 최적화 전략 등을 설명합니다. 또한 LLM 모니터링에 대해서도 다루고 있습니다. 이를 LLMOps라고 소개하고 있습니다. 전체적인 단계를 아래 이미지처럼 요약하고 있습니다. 이런 생성형 AI 애플리케이션 서비스 제공 시 알아두면 좋을 실전 팁들을 전해줍니다.
6장 성공적인 생성형 AI 도입의 열쇠
성능과 비용의 균형에 대한 이야기로 시작하며, 생성형 AI 팀 구축 시 미리 보면 좋을 디테일을 설명합니다. 또한 미래 트렌드도 이야기해 주고 있습니다. 전문가 혼합 모델(MoE), 멀티모달, 에이전트를 미래의 트렌드라 하여 설명해 주고 막을 내립니다. 사실 미래의 트렌드라기보다 지금 제일 핫한 부분이 아닌가 싶어서 의아했는데 원서의 책 최초 발행일이 작년 5월이라 미래의 트렌드로 분류된 것 같습니다.
다른 LLM 관련 책이 word2vec부터 LLM까지의 역사 설명에 꽤 많은 페이지를 할애하는 데 반해, 이 책의 경우 이런 부분을 짧게 지나가고, 좀 더 비용, 최적화, 성능향상, 튜닝 등 실제 업무에서 고민하게 될 부분에 초점을 맞추고 있습니다.
대상 독자
책 서두에 대상 독자를 보여 줍니다. 독자리스트를 보시다시피 간단한 내용을 다루는 초보자를 위한 책은 아닙니다. 중간에 프롬프트 엔지니어링을 다루는 내용도 있긴 하지만, 프롬프트 엔지니어링에 대한 디테일보다는 서비스 구축, 비용, 최적화와 같은 부분을 더 자세히 다루고 있습니다.
그런 이유로 어느 정도 지식이 있는 상태이거나 AI 관련 팀을 꾸릴 때 보시길 권장합니다.

마치며
챕터 6에서 설명한 것처럼, 작년 5월에 나온 책이기 때문에 정보가 최신화되어 있지 않습니다. 예를 들면 모델 비교에는 https://artificialanalysis.ai/ 같은 좋은 서비스들이 있지만 작년 Q3에 런칭된, 즉 책이 출판되고 나서 나온 사이트라 책에는 언급되지 않습니다.
특히 현재 AI의 경우 이틀이 멀다 하고 새로운 게 나오기 때문에, 이 책을 통해 최신 정보를 얻기보다는, 어떤 식으로 팀을 꾸릴지, 인프라를 어떻게 구성할지 등에 대한 갈피를 잡은 후 다시 최신 트렌드에 대해서 알아보시면 좋겠습니다.
![[도서 리뷰] 러닝 랭체인, 랭체인과 랭그래프로 구현하는 RAG, 에이전트, 인지 아키텍처](/_astro/review-learning-langchain-20250629212214926.MxZbPAfN.webp)
![[도서 리뷰] 쉽고 빠르게 익히는 실전 LLM](/_astro/review-quick-start-guide-to-llm-20240323135848844.DD89iW6Z.webp)
![[도서 리뷰] 그림으로 배우는 생성형 AI](/_astro/review-visualizing-generative-ai-cover.BA0TjpHs.webp)